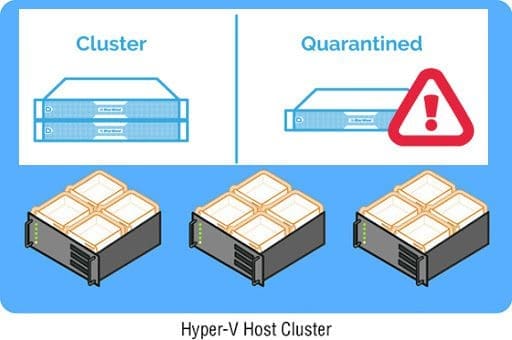
In this artilce, we shall discuss “Quarantine state in Windows Failover Clusters: How to resolve quarantined Cluster Node on Hyper-V”. Windows Server 2016 introduced some “Node states” and one of which is the Quarantine state. Please see A boot image was not found for HyperV Virtual Machine, and Pass-Through Authentication Authentication and ADFS environment setup on Hyper-V for Hybrid Identity integration.
The Quarantined nodes are roles that are drained to other nodes in the cluster and they are not allowed to rejoin the cluster for about two hours. The notion behind this is to stop failing nodes from bouncing up and down (flapping), joining, and leaving the cluster over and over again causing performance issues.
Here is the error message that is being generated "Cluster node '%1' has been quarantined. The node experienced '%2' consecutive failures within a short amount of time and has been removed from the cluster to avoid further disruptions. The node will be quarantined until '%3' and then the node will automatically attempt to re-join the cluster. Refer to the System and Application event logs to determine the issues on this node. When the issue is resolved, quarantine can be manually cleared to allow the node to rejoin with the 'Start-ClusterNode –ClearQuarantine' Windows PowerShell cmdlet. See the following guide on how to install and configure iSCSI Target Server and iSCSI Initiator on a Windows Server, Below are some related HyperV guides: HyperV – Unable to create a new VM, Unable to shutdown a HyperV Virtual Machine, Backup: How to create a HyperV checkpoint, and Unable to PXE boot a HyperV VM: F12 key does not work anymore,
Enhancing Virtual Machine Resilience: Understanding the Quarantine Feature in WS 2016
As discussed before, this is a new feature which was implemented in WS 2016 and relates to Virtual Machine Compute Resiliency. Basically, after 3 failure events, the problem node becomes quarantined instead of isolated. QuarantineThreshold is configurable meaning, by default, it is 3.
During cluster flapping, the cluster restricts quarantining to a maximum of 25% nodes. The exception to this rule is if you have a 2 or 3 node cluster. In that case, the cluster will allow quarantining one node.
The screenshot below displays: Node Name – %1, Consecutive cluster membership losses – %2, Automatic quarantine clearance time – %3. For all Failover Clustering system log events.

In cluster events, you can see the following event details.
When the node experience disruption three (3) times which is the default value of QuarantineThreshold within consecutive failures in an hour.The cluster removes the node to prevent disruptions and provides an automatic quarantine clearance timestamp.
Solution to resolve quarantined Cluster Node on Hyper-V
To view force clear a quarantined node, we can use the Failover Cluster Manager or PowerShell as shown below.
Failover Cluster
Click on the Node as shown below, right click on the Quanrantined node and select “More Actions” and Click on Start Cluster Service.

Power Shell
You can also clear the Quantine node via the PowerShell with the following command below. View and change the default 2-hour setting using PowerShell commands.
Import-Module FailoverClusters Start-ClusterNode –ClearQuarantine
I hope you found this blog post on “Quarantine state in Windows Failover Clusters: How to resolve quarantined Cluster Node on Hyper-V” helpful. Furthermore, If you have any questions, please let me know in the comment session.





Nicely explained. Thanks mate.
You are welcome!